A software engineer based in Surabaya, passionate about all things software-related.
As some of you probably already know, I joined Nodeflux on the middle of February this year as a Software Engineer intern. Well guess what, it's already been 4 and a half months since then and I'm nearing the end of my internship period which only lasts 5 months.
I've already written about my first impression at Nodeflux in this blog post. I initially planned to make a series of blog posts out of my internship experiences here, but unfortunately up to this point it didn't go as planned :p
But I guess it would be weird if there's a short-lived series on my blog which has an opening but doesn't have a closure, so this post is intended to fill that role. It ain't perfect, but at least the story has a beginning and an end.
What I Did in the Last 4 Months
On my first blog post, I mentioned that for the first month and the beginning of the second, what I did was mostly a research effort which requires little to no collaboration. However, the following months were vastly a different experience, it was filled with meetings, discussions, collaborations, and a new set of technical and personal challenges.
Here's the story.
Brand New Projects
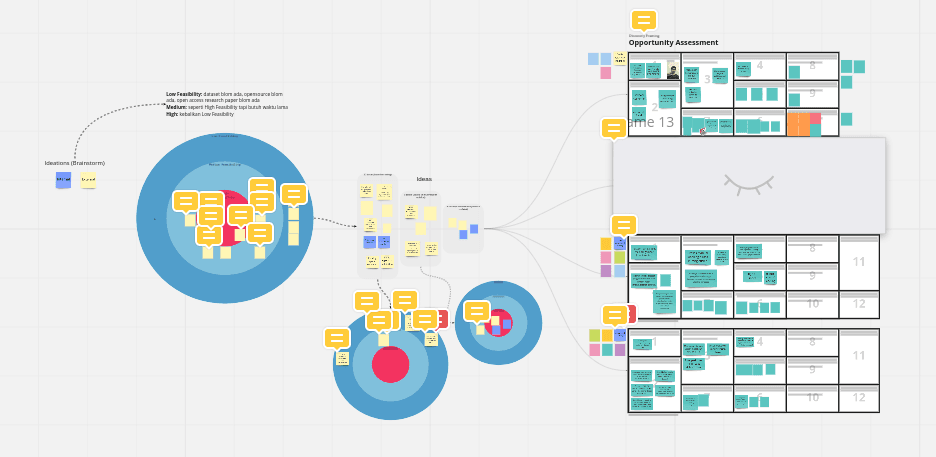
After the that period, we interns were offered several project ideas by our mentors. We were initially offered 5 projects in which we got to pick 3 of them to work on. But we were not sure which to pick at that time, so our mentors gave us the freedom of coming up with our own ideas present the result to them. Then we expanded it to over 20 ideas ranging from totally feasible to not-so-feasible ones. Here's a peek of our ideation board:

From over 20 ideas, we narrow it down to the top 10 based on votes, then to top 5 based on feasibility, and then to top 4 based on impact. Actually we were supposed to narrow it down to the top 3, but we were uncertain between 2 ideas that we thought were equally good. In the end our mentors help us to determine which one to pick, which left us with the following final ideas:
- Selfie with Citizen ID Validation
- Semi Automated Labeling
- Automated Retraining
The Teams
There were 11 interns in the tech division, composed of 3 Product Managers, 6 AI Engineers, and 2 Software Engineers. After we picked 3 project ideas we will work on, we were divided into 3 teams consisting of a Product Manager, Software Engineers, and AI Engineers. The following is the exact composition of each team:

Outlined in green are teams I was involved in as a Software Engineer. There's a little bit of twist though, for Team A, the project were changed from Selfie with Citizen ID Validation to Dynamic OCR because as it turns out, the functionality were already present on Nodeflux's products. I'm not gonna explain what is Dynamic OCR though, because I don't even understand fully what it is 😬
Anyway, the other teams stays the same.
Semi-Automated Labeling
As part of Team B, this is one of the project I was involved on. So, dataset labeling is a tedious process, annotators go through images one by one by one labeling each object of interest on each image. Now imagine getting tasked to label a dataset consisting of many many images, like hundreds or thousands of unlabelled data or even more. Clearly this process would take a while and it doesn't scale when done by human annotators. This project is exactly aimed to solve that problem.
The basic idea is, use a more powerful model to correct bad predictions made by less powerful model. The following is a high level diagram of the whole process:

The core functionality isn't that much, so we decided to add several new functionalities to accompany the core functionality. Built using Streamlit for fast prototyping, these functionalities are:
Model Registry
This functionality exists to make it easier to prepare a model to be deployed as annotator model to CVAT, it utilizes GitHub repo and GitHub releases.
Model Deployment
CVAT has its own deployment mechanism for users who want to use annotator model, but it's not so straightforward and requires scripting, so we decided to make a GUI to make this process easier. This functionality take the model from model registry and deploy it to CVAT.
Dataset Uploader
This functionality exists to provide another way of getting a new dataset to CVAT aside from the buffer service, this functionality also creates a dataset repository for the dataset in the process.
Label Evaluator
This part kicks in after the automatic annotation process is done. This functionality exists to make label evaluation easier by visualizing the annotation result using FiftyOne accompanied with filter-by-embedding functionality.

Dataset Versioning
After the previous steps are done, the only part left is to version the new dataset. This functionality exists to make it easier to version new datasets by automatically creating new versions and automatically generate dataset summary in a readme for easier inspection.
Automated Retraining
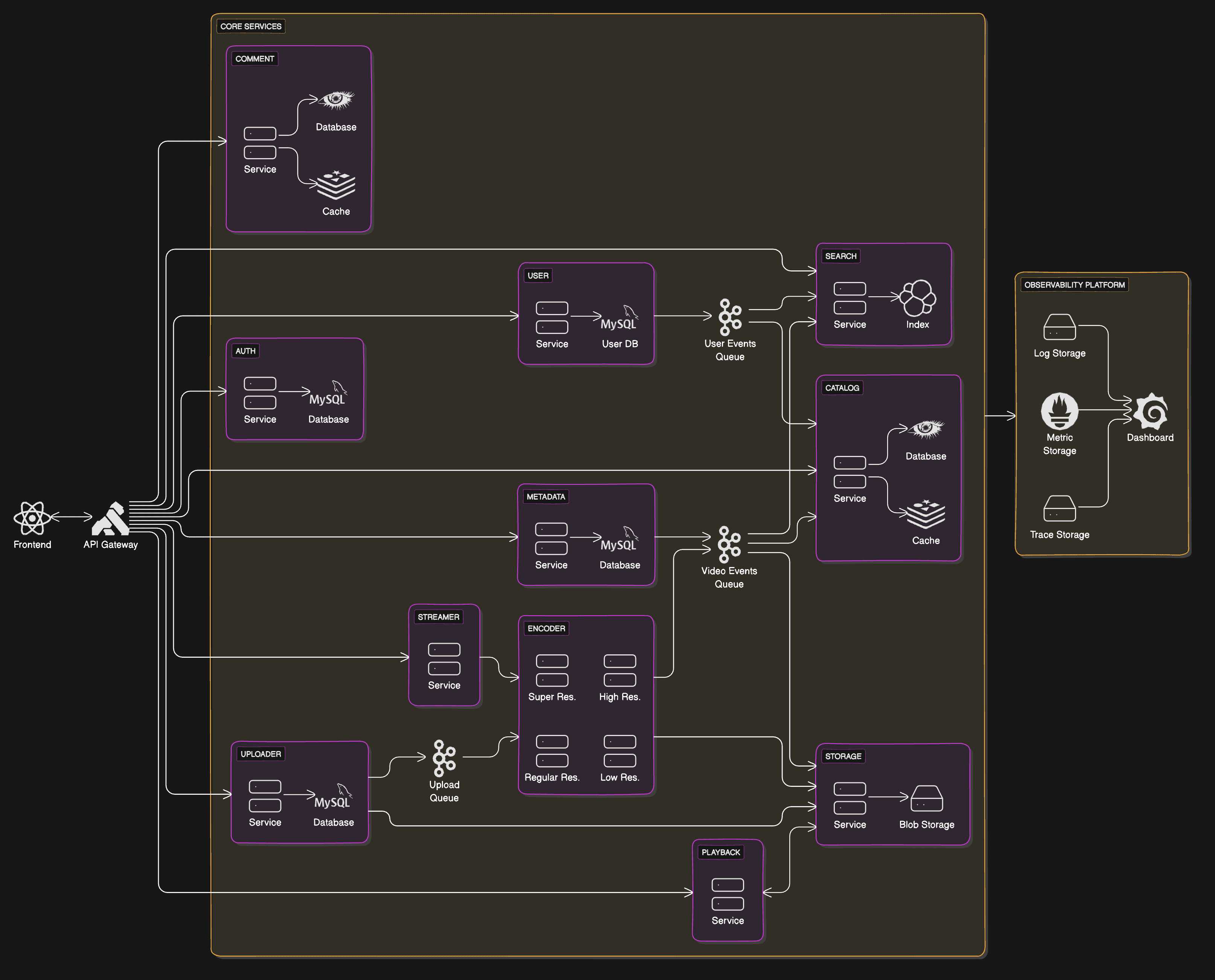
From what I know, retraining a model is not so straightforward either. There are quite a few things todo from setting up the environment, getting the weights, getting and splitting the dataset, tracking the training and metrics, reproducing the training, hyper parameter tuning, to name some of them. This project is aimed to provide a platform where training can be done automatically by being triggered by other systems as well as to provide a centralized platform for tracking the training results. The following is a high level overview of the system:

As you can see, we rely heavily on MLflow to do the heavy lifting. This is mainly done because it is more efficient to use existing tool than to reinvent the wheel. We do add several functionalities around it to achieve the objectives though, such as:
HTTP Server
To listen for POST request. We design the system to be pluggable whenever and wherever it needs to be used, thus it's not integrated to any other system, rather, other system can just send a POST request with the specified body in order to kick off a retraining sequence.
Discord Notification
A small addition in order to notify people when a training sequence has started and finished, it also posts several metadata such as the experiment name, the git uri of the model, the commit hash that got checked out and the URL to the experiment.
Auto Registering Model
If the new model is better than the previous model for a chosen metric, the model will automatically get registered as new version on MLflow's model registry.
Examples
Other than those, we also put together a few examples of how to adopt the system, what are needed, and what code to put in the training script.
So How was it?
There are several things that makes this internship worthwhile for me.
Working Culture
Since the early period I have the impression that Nodeflux is a fun place to work at, and I'm glad it stays that way until the end of my internship. The working culture is nice and it suits me well. Flexible working hour, less bureaucratic, I got my first Eid al-Fitr celebration package from a company, and the internship period was filled with numerous online activities to keep us engaged and to know more about each other (shout out to the People and Culture team 🙌)
Teammates and Mentors
One very nice aspect of this internship is the people. My teammates are fun and are a blast to work with, even if I never get to talk with them face-to-face, it was still fun working with them. Our mentors are awesome too, they are kind and are there to guide us to the righteous path. They gave us quite the freedom, challenges, valuable feedback and lessons, as well as play the role of keeping things under control. Kudos to you guys!
A New Domain
I was never a big fan of AI for some reason and I've been keeping my distance from it for quite some time. But after this internship, I gain new perspective on AI as a subfield of computer science, what it looks like on closer inspection, how things works, what tools does the engineers use, how an AI company operates, what kind of efforts and initiatives are needed to support this kind of company's engineering practices, what are their challenges, and many many more.
In short, it makes me appreciate this subfield and the people dedicated to it more.
It's safe to say this internship has brought many benefits and lessons. From the not-so-technical to the very-technical stuff. I got to collaborate with more people, meet amazing mentors, expand my network, learn how to collaborate better, how to manage time and utilize it better, how to communicate my capacity and situations, how to manage workload better, practicing on saying no. Other than that I also got exposed to new tools and languages as well as new practices and paradigms. I think there's no better way to end this post than writing:
Once again, kudos to you all guys! And thanks a lot.