Learning Distributed System by Cloning YouTube: Part 1 - System Design
Spoiler alert: it's more complex than I thought
A software engineer based in Surabaya, passionate about all things software-related.
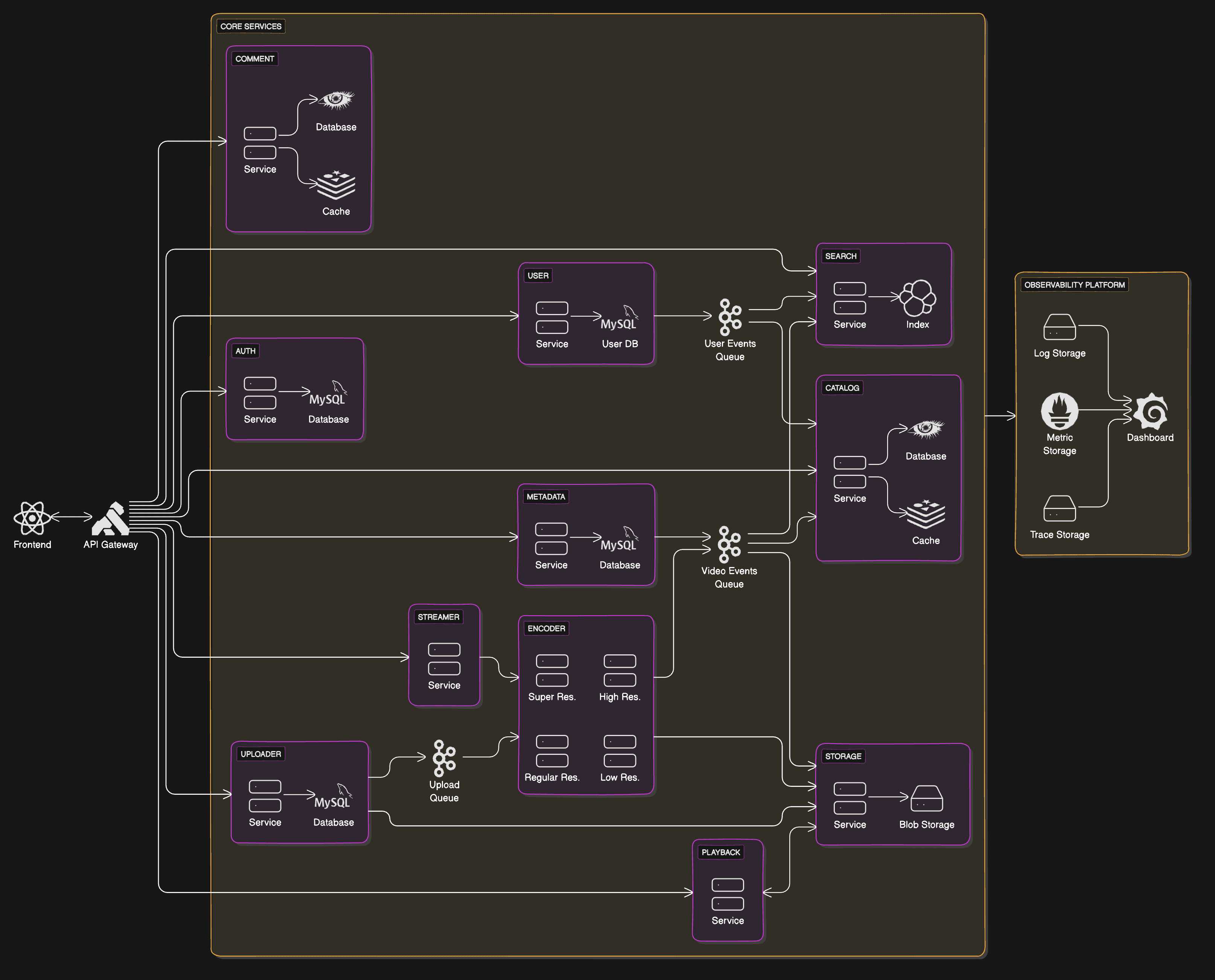
Some readers might furrow their brows when they first glance at the diagram on the cover of the article because it seems so complex. But I want to remind you that this series is a series where I learn distributed systems, so yes, the goal is not to save money or design the most efficient system possible. On the contrary, one of the goals is to do overengineering in the hope of being exposed to plethora of valuable experiences and knowledge from using new tools and from implementing a more complex system than I am used to, so that when I need to create a similar system, I won't end up scratching my head for hours.
Defining Requirements
In this section I decided to take a more commonly used approach in systems design where the functional and non-functional requirements are defined before formulating the solution.
Functional Requirements
Functional requirements are simply the features that are to be provided. As for this system, the functional requirements are as follows:
Users can upload videos.
Users can browse the video catalog.
Users can watch videos in various resolutions.
Users can leave comments on videos.
Users can search for videos.
Users can live stream.
Users can leave comments on live streams.
Non-functional Requirements
Non-functional requirements are the definition of the characteristics that must be present in the system to be built. Here are the non-functional requirements that I have determined for this system:
The system must be highly available.
The system must be observable.
The system must be easily scalable.
The system must be able to handle live streams with acceptable latency.
The system can handle many concurrent users.
The system can handle many concurrent video upload operations.
The system must be able to handle 10 searches a day per user.
The system must be able to handle rapidly growing number of videos with the average upload in MP4 format with an average duration of 8 minutes and a resolution of 1080p.
The system can handle rapidly growing number of video comments.
Now you might notice that these non-functional requirements are vague, and you are right. I intentionally made the non-functional requirements vague and inexact because if I were to do otherwise it would be very difficult task for me to actually verify and prove whether the architecture and the system I made is actually capable of handling such scale. For example, if I were to include the requirement "The system must be able to handle 2 million concurrent requests," which then I proceed to design a solution for, but when the solution is presented it'll be very difficult to prove that the solution can actually handle that exact 2 million concurrent requests, thus making the numbers less meaningful and the solution more of a bogus. But by making the requirements vague, I can get away with just a written argument of why I think my solution fulfills the requirements :p
But then you might also ask "Why define it in the first place then?" Well it's because I still need to get an overview of the usage pattern of the system. One example is the requirement number 8 which indicates that most videos that will be uploaded are long-form contents, thus the architectural solution might be vastly different than in the scenario where the uploaded video will be mostly short 30 seconds contents.
Solution

The image above shows the solution I formulated based on the functional and non-functional requirements above. There are approximately 11 core services consisting of:
| No. | Service | Function |
| 1 | Auth | Handling authentication-related stuff |
| 2 | User | Handling operations involving user data |
| 3 | Search | Handling video searches |
| 4 | Uploader | Handling video uploads |
| 5 | Encoder | Handling the encoding of the uploaded videos |
| 6 | Storage | Handling the storage of the videos |
| 7 | Catalog | Handling the browsing of video catalog by user |
| 8 | Metadata | Handling operations involving video metadata such as editing description and title |
| 9 | Playback | Handling playback request from user |
| 10 | Comment | Handling operations involving comments of a video |
| 11 | Streamer | Handling live streaming |
Decisions, Trade-offs, and Other Considerations
Cassandra for the Database
Perhaps one thing that is very visible in the diagram above is my decision to use Cassandra to store data in the Catalog and Comment services. This is based on the non-functional requirements which show that the number of videos and comments on the system is expected to grow rapidly. Therefore, a database is needed that natively supports sharding well and is easy to adopt so that the system can cope with the rapidly growing data. With such data growth characteristics, I see Cassandra, which provides ease of data partitioning, the ability to handle large-scale data, and designed for horizontal scaling from the ground up, as a suitable technology to use in this case.
Perhaps some readers will ask, "Then why are there still services that use MySQL? Why not replace Cassandra with MySQL or vice versa? Isn't there Vitess that can be used to make the MySQL sharding process easier?" This is a valid question. And the answer is that I still use MySQL even though other services use Cassandra. In addition to the capabilities of Cassandra itself that are suitable for these services, the second reason for choosing Cassandra is that I want to adopt new technology. And the reason I'm sticking with MySQL for some servcies even though I want to adopt new technology is that I also want to try using Vitess with MySQL, so that hopefully I will be exposed to more technologies that will broaden deepen my expertise and engineering wisdom.
Kafka for the Message Queue
Another thing that is very visible is my decision to choose Apache Kafka exclusively to handle all queueing needs. The decision to use Kafka exclusively here is based on the results of my brief research which concluded that for large-scale Kafka is more reliable than similar options like RabbitMQ. Kafka can easily handle petabyte-sized data and is designed from the ground-up to be horizontally scalable, thus making it a good choice for a system that is expected to scale.
If you look at the diagram above, there are three places where Kafka is used, namely as a queue for processing user-uploaded videos, another instance that acts as an event bus for video-related events, and another instance that acts as event bus for user-related events. The Kafka instance that acts as an event bus will accommodate the storage of events such as video deletions, video creations, video editions, user deactivation, and so on. Services that have an interest in these events can connect as consumers and do what they need to do every time the desired event occurs. A concrete example is the Search service that is connected to the event bus can listen to the video deletion and user deactivation event, and when that event occurs it can delete the index of the deleted videos or the videos of the deactivated users.
Paralellizing The Encoding Process
The Encoder service works by taking data from the uploaded video queue, processing it, and the final result is the uploaded video in different formats and resolutions. Interestingly, in this service the encoding process for each resolution is done in parallel. This decision is based on the non-functional requirements above which states that the average video length is 8 minutes and the average uploaded resolution is 1080p. If the encoding process is done sequentially, it will certainly take longer and the time required to complete the process will increase drastically as the size of the video increases. Therefore the process needs to be parallelized so that it can be made faster. In addition, by making one server handle just one type of encoding, the specifications of each encoder server can be set and adjusted in accordance with its needs. For example, encoding with high resolution can be done using a server with high specifications, and the lower the resolution, the workload can be handled by a server with lower specifications. Thus providing a more hypothetical benefit of cost-saving.
Caching Layer
In some services such as Catalog and Comment, it can be seen that Redis is used as a caching layer. Perhaps seeing this, some readers will ask, "Why don't all services use caching?" The answer is that for now, the services that I feel interact the most with users are the Catalog service because users will often browse the video catalog, and the Comment service because every time a user watches a video, the comments on that video are also taken from the Comment service. By utilizing Redis for these services, the latency can be kept as low as possible.
As for other services, I have not yet seen the benefits of using a caching layer. It is possible that in the future I will add it if I see the benefits.
Handling Live Streams
If you look at the system design references for a live streaming system like this on YouTube, you will usually find the use of PoP servers, or point of presence servers. These are servers that are spread all over the world and act as the first point of contact for users who want to do live streaming so that live stream data from users can reach the system's internal network more quickly. This PoP server sends the data using a high-speed network to another server that is responsible for processing live stream data into multiple resolutions and formats and saves it. When user wants to watch the live stream, they can connect to a nearby PoP server, the PoP server will get the stored video from the core system and deliver it to the users. The flow is roughly as follows:
However, in this series, I do not yet have any plans to use this server, because it requires physically deploying the server on various geographical locations, which means using cloud computing. I avoid this because I don't want to spend a lot of money while writing this series.

In addition, something else that is perhaps quite clear from the diagram above is the decision not to use a queue when processing live streams. This decision was made so that the screen-to-screen latency can be reduced and be more predictable, because if the data from the user's live streaming session has to queue in the same queue as the uploaded videos of other users, then the following two things will happen:
The latency will be slower than if the encoding process is done directly without going through a queue first.
Latency becomes less predictable because it will depend heavily on how many entries are in the queue.
Last thing I want to note is that, as for the protocol that I chose for handling live streaming is the RTMP protocol. This protocol is the most popular protocol for live streaming needs and is the live streaming protocol used by large platforms such as YouTube, Twitch, Restream, and many other platforms.
The Observability Platform
I see this project as a golden opportunity to practice the material that I learned from Imre Nagi's (@imrenagi) Software Instrumentation bootcamp. I'm curious about how to build a system that already considers observability from the start.
As for the choice of technology itself (LGTM Stack), it is purely based on my familiarity with it. In the bootcamp I mentioned above, we were introduced to some tools from the LGTM Stack such as Loki and Grafana. Therefore, I decided to continue with it by adopting other tools from the LGTM Stack, namely Mimir and Tempo.
How Do You Eat an Elephant?
Honestly, I'm a bit surprised by the complexity of the solution I've come up with. But I guess that's part of the learning process and a challenge in and of itself. If I can implement it fully or even extend it, I will gain a lot of valuable tinkering experience (and a bunch of new writing and side projects to fill my resume :p). Additionally, the architectural design might change as the series progresses. It could become simpler, or maybe even more complex (lol).
But still, there's one question that kept nagging me during the architectural design process: "How can I possibly swallow all this?" I thought, because honestly, the complexity feels very overwhelming. But then I remembered a saying that goes something like this:
"How do you eat an elephant?"
"One bite at a time"
So the approach I'm going to take is to break down the complexity of the system into smaller, more manageable chunks, and focus on just one problem at a time. This might take a long time, but I think that's okay as long as I keep learning new things along the way.
In the next part, I'll start working on the Uploader service first, as this service is one of the most important one.